
| Handbook for Agrohydrology (NRI) | ||||
| Chapter 8: Data analysis | ||||
| (introduction...) | ||||
| 8.1 Statistical methods and data analysis | ||||
| 8.2 Non-statistical analysis of agrohydrological data | ||||
| Appendix E: Data analysis | ||||
|
| ||||||||||||||||||||||||||||||
Although runoff information is most important to the hydrologist, it cannot be treated in isolation and many of the methods of analysis used on runoff data are commonly applied to other types of information. The analysis of all data is extremely important because it can be used to understand why and how processes happen, though many statistical methods ignore the understanding of behaviour and focus upon probabilities, fitting data to particular distribution patterns, the form of which can be defined. Knowledge of both the processes that take place and statistical methods used to predict hydrological behaviour should be sought. A knowledge of statistics is essential in data analysis, and in this chapter a deliberate attempt has been made to include a comprehensive explanation of statistical methods while at the same time avoiding over-detailed statistical theory. The intention is to help in the selection of the correct techniques of analysis and explain how they are used.
The desire to understand the complex inter-relation of hydrological processes and, later, the temptation to ignore this complexity for statistical methods has led to three main approaches to the study and treatment of hydrological data.
Deterministic Hydrology: assumes that certain influences determine the passage of rain to its ultimate destination, and that the physical environment is responsible for the presence and level of importance of these influences. No concept of probability is involved, although where deterministic models are used, their accuracy is defined by statistical parameters.
Probabilistic Analysis: defines the chance of particular values of data occurring. It is independent of time and sequences of events do not carry any significance.
Stochastic Methods: recognise that probability plays a large part in the nature of hydrological data, but also that the sequence of the data also carries significant information. In many instances, this type of analysis may be regarded as a combination of the two other methods.
Hydrological data are stochastic in reality, but it is easier to deal with them, mathematically at least, if they are regarded as probabilistic or deterministic. Stochastic data represent a time series that may be viewed in discrete periods or continuously. The daily, monthly or yearly flow hydrographs are good examples.
An understanding of hydrological processes enables a pattern to be fitted to runoff events that have numerical values. This pattern-fitting is used to predict hydrological behaviour and is often referred to as "modelling", though the term is often over-used; a simple regression that states that 20 mm of rainfall on a given catchment will produce 100 m³ of runoff under particular conditions will often be referred to as a statistical "model".
It is not surprising that hydrological analyses and models have become progressively complex. The attempt to derive models that can be generalised for use in many geographical regions, yet at the same time give accurate results, demands complexity, but could be regarded as self-defeating. In addition, many hydrological data must by analysed in a manner that cannot be regarded as "modelling" in any mathematical sense. These analyses are essentially the treatment of data to provide further information or to render basic data into more useful forms.
It is important however, to evaluate carefully the needs that are required for a particular project. The simple treatment of hydrological information, collected in the area for which results will be applied, can be far more useful to agricultural development than complex, imported models generalised from parochial results.
For many projects the cost of data collection (both in money and time) and the duration of records will impose severe limitations on the analysis of data and the development of models. For example, the simple linear regression of daily rainfall against runoff not only provides a causal relation, the accuracy of which can be quantified, but in the context of long-term daily rainfall records (which are usually available in most countries) can give an acceptable probability basis upon which to plan field layouts and runoff control. The data collected from many projects may not be adequate to allow a more sophisticated treatment. The following chapter concentrates on the important analyses that should be considered when agrohydrological information is being studied.
This chapter is subdivided into two main sections:
8.1 Statistical Methods and Data Analysis
This section deals with the statistical methods that are essential techniques in the analysis of data and provides examples of particular statistical methods to ensure that the general forms of analyses which are described, are fully understood. The data under study and which is used to provide examples are hydrological data. However, these statistical methods are applied to other information, most commonly rainfall information.
8.2 Non-Statistical Analysis of Data
This section discusses methods by which data that are not amenable to statistical treatment are prepared and studied; often these treatments are concerned with changing basic information into a more useful form. Sections on the analysis of hydrological, rainfall and meteorological, evapotranspiration and sedimentation data are included.
There are several kinds of hydrological data that may be collected. The quality of these data will be determined by various errors.
Random Errors: cannot be avoided, though good practice keeps them to a minimum. They are assumed to have a statistically normal distribution, that is that there are as many low values as high values distributed around the mean, and that there are more values close to the mean than at the high and low value extremes.
Systematic Errors: usually show an increasing or decreasing trend, for example reduced water depth measurements due to the progressive stretching of a measuring cable.
Non-homogeneity: is not an error as such, but effects the values of time series data in a progressive way. It may be due to changes in catchment characteristics; for example progressive de-forestation, causing a trend of increased runoff.
The term "population" is often used in statistical analysis and is used to describe the variable values that are under consideration, the sample population may be regarded as a selected group of those values that are used.
8.1.1 Elementary Statistical Properties
Mean, Median and Mode
The arithmetic mean is a widely understood idea. It is easily calculated and is the usual method of describing the "central tendency" of a group of data. With distributions that have a small sample of very high or very low values, the mean may be greatly influenced by these values and may not accurately reflect the central tendency of the data, a situation often found with runoff and rainfall data which often have a few, very high values.
The median value is that which falls exactly in the middle of a range of values and not is affected by the weighting of a few extremely small or large values. Hydrological data often takes this type of distribution and therefore the median is frequently used.
The mode is the value in a group of data that occurs most frequently and used in extreme value asymptotic functions.
Standard Deviation and Coeffcient of Variance
The standard deviation is a measure of dispersion of values of a variable "x" around the mean value. It is the square root of the mean-squared deviation of individual measurements from their mean and is defined by the equation for unbiased standard deviation, which is preferred:
xxxxxxxxxxxxxxx(8.1)
where x = mean of x
It may be regarded in a non-statistical
sense as the "average" value of dispersion of values from the mean.
Figure 8.1 below shows a set of time series data with the arithmetic mean and standard deviations. One standard deviation + and - the mean represent the 68% level confidence limits.
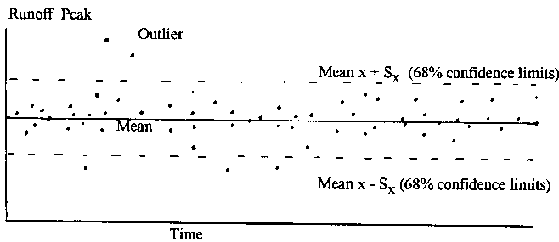
Figure 8.1: Elementary Statistics of
Time Series Data
The standard deviation is denoted by d. The standard deviation
of a sampling distribution is the standard error. The standard error of the mean
= 
xxxxxxxxxxxx(8.2)
and standard error of the standard deviation is = 
xxxxxxxxxxxxx(8.3)
The variance is the square of the standard deviation. The coefficient of variation is a dimensionless measure of the dispersion around the mean and is defined by:
Std dev, -Sx/ 
xxxxxxxxxxxx(8.4)
Statistical computer programs and many electronic calculators give these parameters as a matter of course, though they may be calculated manually if necessary.
Skewness
The lack of symmetry of a distribution around the mean is called skewness. The skewness of the population is defined as:

xxxxxxxxxxxxxx(8.5)
The unbiased estimate of skewness from the sample is given by:

xxxxxxxxxxxxxxxxx(8.6)
8.1.2 Correlation Analysis
Correlation analysis measures the association of one variable with another; and is often used to define associations between several variables. The table that defines these relations is called a correlation matrix and is a standard part of the output of statistical analysis computer packages. The variation of both (or all) variables is not fixed by the observer nor by control and unlike regression analysis, correlation does not pre-suppose a causal relation between the variables. Because no inference of causality is present, correlation does not allow the prediction of values of one variable from another (as does regression), by the use of a formula that describes the correlation. However, correlation defines association and has a practical application; it is used to select variables that are suitable for multiple regression analysis.
For example, it may be required to obtain an equation by multiple regression (using previously collected data) that will predict runoff amount, given that values for rainfall amount and catchment physical characteristics are available. Table 8.1 illustrates this. A number of variables, obtained from catchments in Belize, Central America, were used in multiple correlation analysis were used in this example.

Table 8.1: Correlation Matrix of
Hydrological Variables
It can be seen that pairs of variables such as catchment area (AREA) and mainstream length (MSLE); stream frequency (STRFQ) and the soil/slope index (SOS); Average main stream slope (AMSSL) and basin slope (BSL), are highly correlated. In regression, variables used as "independent" variables should be independent of each other and should not be significantly correlated. It is not be appropriate to use highly correlated variables, such as those in the example pairs, together in the same regression analysis. The inclusion of correlated variables does very little to improve the quality of the resulting equation.
The numerical value that describes relations between variables is the "correlation coefficient", 'r' and relates to the sample data. Correlations can be positive or negative. As the number in the sample becomes large the distribution of the standardised variable "t" can be used to test the significance of the correlation (Student's "t" test).
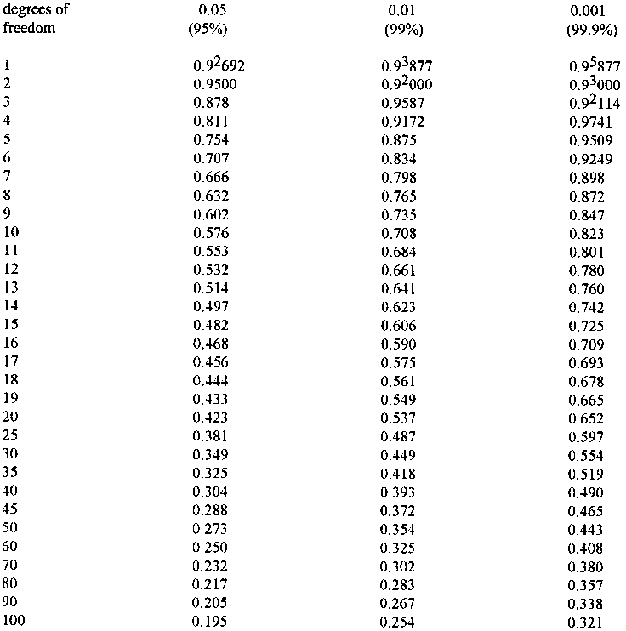
Table 8.2: gives data for testing the
significance of correlation between variables. They may also be used for testing
significance in regression analysis.
Correlation Significance Examples:
a. SOS (soils/slope index) and STRFQ (stream frequency in terms of number of streams per square kilometre) have: a correlation coefficient, r = 0.961, n, the number of data points (or "sample size") = 15 degrees of freedom (d.f) = n - 2 = 13From Table 8.2, variables with a correlation coefficient greater than 0.760 are significantly correlated to the 99.9% level (0.001) and these variables would not be suitable for simultaneous inclusion in regression analysis. Indeed, even a significance level of 90% (0. l)would justify their mutual exclusion.
b. SPFN (floodplain area) and RSMD (a soil moisture deficit index) have: r, = 0.158, n = 15,d.f = 13
From Table 8.2, the relation is not nearly significant even at the 0.1 (90.0% ) level and these variables would be suitable for simultaneous inclusion in regression analysis. Standard textbooks on statistics provide a more detailed background on the "t" distribution and limiting conditions for its use.
Table 8.2: Table for Testing the
Significance of the Correlation Coefficient 'r'
8.1.3 Regression Analysis
Methods Usually Adopted to Estimate Flow Volumes
a Simple Regression
Regression analysis is a widely used method to derive formulae that define the relation between two variables and unlike correlation analysis, admits this relation to be causal. Very many of the predictive or relation equations found in the literature and that link hydrological parameters are in fact regression equations.
Regression analysis is often seen as a simple x-y graph, but with distributions of real data, it is rare that all the data points fit exactly on the line of best fit drawn through them. An even balance of points on, above and below the line is sought, with the line drawn to minimise the dispersion of points around the line. The method of "least squares" is used to draw such lines, and although regression and the least square for each point can be calculated manually, computer programs that provide a best fit in this way are so common that manual calculation is almost obsolete. A standard textbook on statistical techniques will provide examples of these manual computations, if desired.
The values of the independent variable are plotted on the x axis (in this case rainfall) while the values of the dependent variable (runoff) are plotted on the y axis. The initial step is to plot a scatter diagram of values of y on x. This gives a visual idea of whether a significant relation between the two variables may exist, but does not define it. Statistical computer packages (and sometimes graphics packages also) are widely available to plot scatter diagrams and undertake regression. They will also provide numerical values for equation 8.1, evaluate the significance of the relation and quantify residuals (the errors in the fit of the regression line) and confidence limits. The form of the equation of simple regression is:
y = a + b (x) where (8.7)
y = runoff
x = rainfall
a = intercept value
b = gradient of the graph (a and b are known as regression coefficients)
The selection of variables for regression is based on a reasonable assumption that a variation of the independent variable will cause a variation in the dependent variable. A good example is the relation between rainfall and runoff; it is most important in the runoff process and the starting point for most runoff analyses. Figures 8.2 (a) and (b) show examples of linear regression using daily rainfall and runoff values from two rangeland runoff plots of 0.4 ha extent. The details of the relations are given.
|
(a) y = 1.0497x - 6.30 |
(b) y = 0.1266x +1.16 |
|
n = 44 |
n = 10 |
|
R2 = 0.83 |
R2 = 0.34 |
|
P<0.001 |
P>005 |
The relation is significant to the 99.9% level
The relation is not significant to the 95% level
In the case of graph (a), a significant linear relation may be assumed from the distribution of the data points. When the regression analysis is complete this significance is verified to the 99.9% level. This indicates that there is a less than a one in one thousand chance that the distribution of these data points is due to chance and indicates a strong causal relation between the amount of rainfall and the amount of runoff. The value of R2 (the coefficient of determination) indicates that the variation in rainfall explains 83% of the variation in runoff.
No definition of the influence of other catchment factors which determine the amount of runoff from a plot such as this (soil texture, slope, vegetation cover etc.) can be made, other than that, combined, they account for the remaining 17% of variation.
The distribution of data points in graph (b) may appear to show a significant relation, but the value of R2 is 0.34 and testing shows that this is not significant to the 99.9% level, nor even to the 95% level. There is more than a one in twenty chance that the relation is explained by chance, rather than the influence of rainfall amount on runoff amount. The selection of significance levels is one of subjective choice. As a hypothetical example, the relation of graph (b) may be significant at the 50% level, but this admits that chance is as likely as not to be responsible for the apparent relation. In general, the 95% level is the lowest accepted, though the convenience of the 68% level of confidence being equal to the mean + / - one standard deviation results in its occasional use.
The availability of data for analysis is an important consideration in experimental planning and the collection of data. Analyses with very few data points need very high values of R2 to assure significance, since the number of degrees of freedom (d.f.) are = n - 2 and with few data, values of d.f. are very small. Graph 8.2 (b) has only 10 - 28 degrees of freedom and its R2 would need to be 0.87 to give P< 0.001 (99.9%), whereas graph (a) with 42 degrees of freedom would only need an R2 of 0.48 or so. Where runoff data are expected to be sparse, for example in arid and semi-arid climates, a single runoff plot that typifies one kind of environment will not be adequate to provide a sufficient number of data for useful analysis, unless it is monitored for many seasons. The data for graph (b) represents the collection of information over three seasons; runoff was rare, some data were lost and the dataset of 10 values is really inadequate for use in regression analysis.
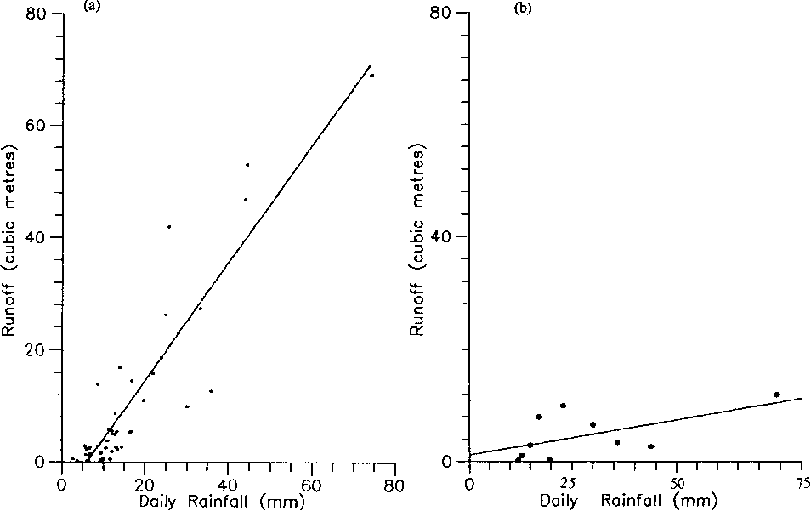
Figures 8.2 (a) and (b) Regression of
Daily Rainfall Versus Runoff
A shortfall of data for large rainfall/runoff events is a particular problem. Such events are naturally infrequent, but are usually of great interest. If the influence of rainfall on runoff is the case under study, there is strong justification for the use of many replicate plots of the same soil, slope, vegetation cover, etc., that are located together and which experience the same rainfall. The data from such replicates could be combined into one dataset and used as though they came from one plot.
The independent variable under study (in this case rainfall amount) should be allowed to range as widely as possible, while the values of all other influences (for example catchment size, slope and vegetation cover) should kept under tight control. This approach requires extensive replication and the cost of construction, instrumentation and monitoring must be balanced against the increase of data that is achieved. The input to collect sufficient data during a project's time, may exclude experimentation in other areas of interest.
Data from catchments that are only generally similar may also be combined so that the range of physical circumstances to which the equations can be applied may be widened, but the accuracy of such equations in predicting the response of the dependent variable will be lessened. Simple linear regression can be undertaken between many factors, though most combinations are likely to involve runoff as the dependent variable.
Goodness of fit
The Chi-square goodness of fit test can be used to decide whether a line fitted by one method of fitting is more accurate than that of another method; for example whether the least squares technique is more accurate than fitting a regression line by eye, or whether one theoretical statistical distribution gives a closer fit than another.
The Chi-square parameter is defined as 
xxxxxxxxxxxxxxxxx(8.8)
Where two different methods of fitting are used, the method with the lowest value of x2 shows lowest dispersion of points around the line drawn and is the most suitable. The use of this test between different regression fits is not so important because of increased computerisation. However, it is widely used to decide whether one statistical distribution (for example Pearson Type III) fits the data better than another (for example the Normal distribution).
For instance, if a Pearson Type III distribution has a X2 value of 4.56 and a Normal distribution has a X2 value of 5.04 for rainfall data, the differences of fit are smallest for the Pearson distribution and it is to be preferred. Moreover, given that the degrees of freedom for the data 'v' (=n -1) is 10, then neither of the distributions can be rejected at the 0.05 (95%) level, a , because the critical X2 value for v = 10, a = 0.05 is 18.31 and the X2 values for both distributions are less than this critical value. Critical values of X2 for various v and a can be obtained from statistical tables in Appendix E.
Confidence Limits
As discussed above, the value of the results obtained from regression can be qualified by testing for the significance of the relation; the higher the significance, the stronger the relation and the more useful the equation will be to predict future runoff amounts. Confidence limits define the range of probable values of any estimate made from a regression equation, and as stated previously, those most commonly used are the 95% confidence limits. These limits are positioned above and below the regression line (+ and - ) and diverge as the values of x (or more correctly [x - mean x] ) increase and are therefore parabolic, but symmetrical above and below the regression line. Where a log transformation of data has been applied, (see below) the confidence limits will not be symmetrically distributed around the regression line. For example, a hypothetical logarithmic regression equation may give the value of runoff 'y' for rainfall 'x' to be in the range, y = 135.6 m³ + 6.8, - 5.3 m³. Thus the value of y will lie in the range 142.4 to 130.3 m³, with a confidence of 95%.
Confidence limits for a range of y values (sometimes called control curves) may be may be calculated manually by the use of a range of x values, but this is an unduly laborious process when large datasets are being analysed. Standard statistical packages usually include confidence limit plotting as a basic feature, though the quality of graphical output varies a lot.
The importance of confidence limits, and also the importance of adequate detail can be seen from Figure 8.3. The logarithmic regression of rainfall against runoff for this graph (in log10 form) is P < 0.001 and therefore highly significant. However, the dispersion of points around the mean is relatively large and the 95 % confidence limits are therefore widely spread. The details of the relation of this graph are:
n = 41
log (a) = -3.26, (se = 0.68)
b = 2.09, (se = 0.28)
R2 = 0.59
The relation is significant to the 99.9% level.
The catchment from which these data were obtained was located at a site in SE Botswana with a resident gauge reader/observer, but only 41 data points could be used for the analysis out of a total of 45. Four data points were lost due to equipment malfunction and silting of the flume, though it is unlikely that 4 extra values of rainfall and runoff would have improved the regression greatly. The main reason for the small dataset, collected over three years, was the semi-arid climate of the region which resulted in infrequent rainfall and an average of only 15 runoff events each year. As can be seen from the graph, it would be foolish to estimate runoff from rainstorms greater than 20 mm or so, because the confidence limits are so wide and only six plotted points represent rainfall equal to or greater than 20 mm However, if interest lay in low rainfall/runoff values, the analysis would be satisfactory and the removal of the higher values would improve the relation of a re-plotted regression and more reliable estimates of low flows could be obtained.
Usually the interpolation or extrapolation of high runoff values that are of interest, however. It must be stressed that in this case the problem lies not with the analysis, but with the limited amount of available information. Serious consideration must be given to experimental planning, so that adequate data are collected.
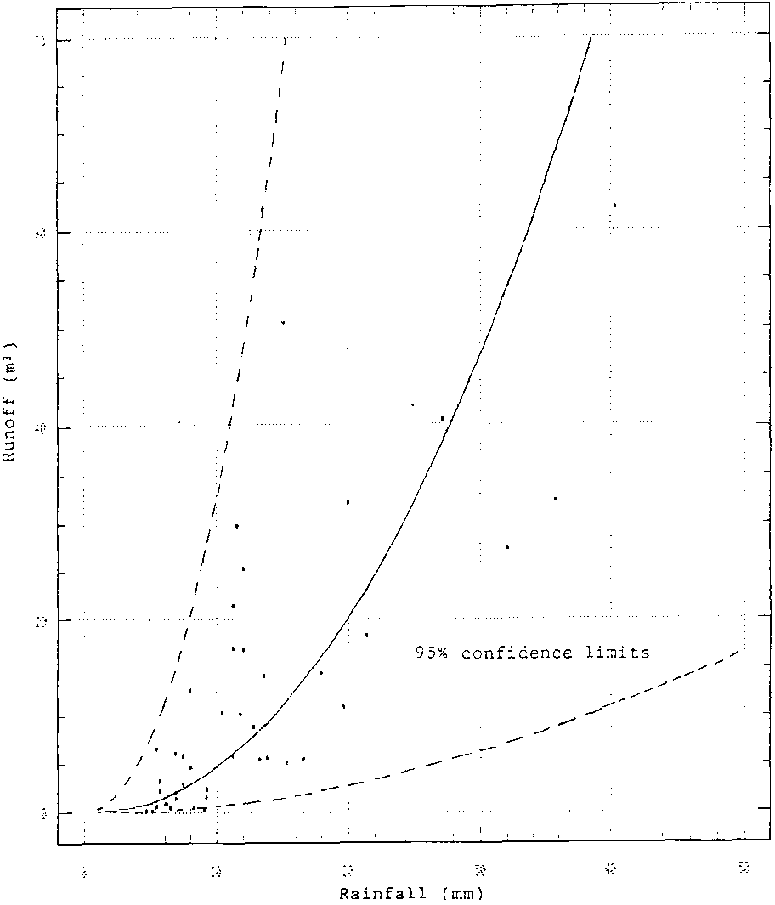
Figure 8.3: Regression of Rainfall
versus Runoff with 95% Confidence Limits
Transformations of Data for Regression
Hydrological data frequently do not exhibit a linear form when plotted, and it is common practice to transform the data before regression is attempted, so as to arrive at linearity. Also, transformation may stabilise variance of the data and render the points along the regression line more homogeneous. A number of transformations are available, but by far the most common is the transformation of the data to the logarithms of the values before regression, such that the equation of the relation becomes:
|
y = axb, that is |
log (y) = log (a) + b [log (x)] |
(8.10) |
y is = antilog log(y)
Research has shown that other modifications of variables (for example the use of (Rainfall) 2 versus runoff) can give improved results in obtaining a descriptive equation.
Isolated data points that conform very poorly to an otherwise good linear relation (these points are called "outliers") can be removed from the analysis if an obvious reason for their inaccuracy can be detected. For instance, errors that commonly cause such outliers may be silting of the flume, inaccurate gauging of a river, a change in the rating curve that has not been corrected or allowed for, or the incorrect setting of a water level recorder. It is important to refer to the original source of information (field data sheets for example) to identify errors, or gather explanatory notes on unusual occurrences.
b. Multiple Linear Regression
It is useful that regression can predict a response in dependent variable y, from the changes in a number of independent variables. For example runoff amount may be estimated from the values of rainfall, land slope, soil texture, soil moisture, etc., by the use of a single equation. The form of the equation for linear multiple regression is:
y = a + b1x1 + b2x2+......... bkxk where (8.11)
x1........xk represent the different independent variables.
Values are entered into the statistical database for the dependent variable y and independent variables x1, x2,..........xk.
The independent variables should not be significantly cross-correlated. The quality of the total regression is described by the coefficient of multiple determination, R2 (the square root of R2 is the multiple correlation coefficient) and values of the standard error of prediction are often given by computer packages. Degrees of freedom for testing for significance of the regression are calculated by using (n - k ) -1, where n is the sample size and k is the number of x independent variables.
It is important to recognise that for each x variable that is added to the regression equation, a degree of freedom is lost. Where the number of data are small, the addition of independent variables can actually be counter-productive, especially if a variable does not improve the quality of regression to any great extent. The transformation of data, for example to a logarithmic base, is also a common preparation for multiple regression analysis. The methods of prediction of values of y is similar to that of simple regression.
Typical computer printout information is shown below using examples from the variables in Table 8.1, the correlation matrix.
Dependent variable, Runoff,
y = 2.69 × 10-4 + Area3.698 + Soil Moisture46.029 + Stream Frequency-7. 441
R2 of the equation is 0.893
Standard error of the estimate of the equation is 0.383, the standard error of the coefficients are, respectively, 1.024, 11.784 and 1.777 with 95% confidence limits of - 83 to + 483.
The data of the equation were transformed to log 10 before regression and runoff is in m³.
Regression analysis is most usually adopted for the prediction of runoff amounts or volumes. Theoretical distributions are most commonly used to estimate peak flows and such distributions are described below.
8.1.4 Statistical Probability Distributions
These distributions are adopted to estimate flows, their probabilities and return periods. The return period of a flow is the reciprocal of its probability. In particular, knowledge of peak flows is essential in the successful planning of water harvesting and field systems and in this context it is the size and frequency distribution of peak flows that are often of paramount importance. The return periods and sizes of flows involved will be determined according to the aims of a project, but most analyses must overcome the almost universal difficulty of working with short periods of data. For example, studies show that 80% of estimates of the 100 year flood, based on records of 20 years, are overestimates. Fortunately, planning for such long return periods is rare in agrohydrology and many techniques of analysis have been developed with the problems of short records in mind.
The analyses applied to predicting flow data are primarily statistical. Two basic questions can be asked with regard to risk and design:
- What is the probability (p) of a flow Q being exceeded during the design life L?
- What is the flow Q which has a selected probability (p) of being exceeded during the design life L?
The study of probabilities attempts to answer these two questions.
Probability Paper
Before looking at the various distributions that can be applied to runoff data, it is important to consider the manner in which these distributions are actually plotted as graphs.
Probability paper is used to plot, manually, cumulative probability (x axis) against a variable (y axis) and is designed so that the data will fall on a straight line, if it actually conforms to the selected distribution. Different types of distributions require different types of paper and such a plot is used as a convenient guide to the interpolation and extrapolation of variables, probabilities and return periods.
In the distributions discussed below Extreme Value Type I and normal distributions are plotted on Gumbell - Powell paper (y axis rectangular, x axis Type b; EV III plotted on Weibull / log. extremal paper (y axis log, x axis Type I) and log-normal distributions are plotted on log-normal paper (y axis log, x axis normal probability).
Where probability paper is not available, the probability scales can be constructed from the equation:
x= mean x standard deviation K, (8.12)
The value of K with corresponding return period Tr can be obtained from the tables provided below, with the discussion on different distributions (note log-normal Pearson Type III with skew = 0). A rectangular scale of K is drawn and the corresponding value of T is transferred to the x axis of the paper. The probability value p is the reciprocal of Tr. The plotting positions according to Weibull or Gringorten are use for EV1 and normal distributions. Weibull is most commonly used for the annual maximum series.
It is likely that the data points will not fit exactly on a straight line and a line of best fit may be fined by eye or regression analysis (the method of least squares).
There is an obvious advantages in the interpolation and extrapolation of probabilities, where runoff data are found to conform to theoretical statistical distributions and any flow can be described by the parameters of the distribution. Many distributions have been studied to discover any such conformity. Hydrological data is usually highly skewed and not evenly distributed about the mean; rather there are usually very many small values and a few, very large values. This has generally precluded the successful use of the Normal distribution, as data in this type are distributed uniformly around the mean. The use of the Log-normal distribution has been widespread in the past, because when transformed, the logs of peak flow magnitudes are commonly seen to be normally distributed. The Log-normal distribution is a special case of the Pearson Type III distribution, described below, with skew equal to zero.
It is not surprising that no particular distribution is universally appropriate for the fitting of hydrological data, though the log-Pearson Type III and the Gumbel Type I (EV1) distributions have been adopted for flood study in the USA and UK, respectively. These two distributions are discussed below with worked examples, though the details of the statistical theory is only given in outline.
Most frequency functions can be generalised to the form: X =

xxxxxxxxxxxxxxxxx + K sd x; where
(8.13)
X is a flood of a specified probability
xxxxxxxxxxxxxxxxx is the mean of the flood series
sd
x is the standard deviation of the series and
K is a frequency
factor defined for each specific distribution and is a function of the
probability of X
a. Log-normal Distribution
This distribution has been used historically, as a suitable distribution for flood flows. It is a transformed normal distribution with the variate data transformed to logarithmic values.
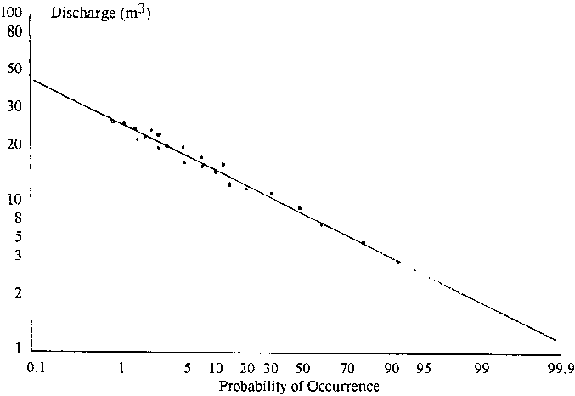
Figure 8.3: Log Normal Plotted on
Probability Paper
The probability density is given by:

xxxxxxxxxxxxxxxxxx where (8.14)
y = ln x,
m is the mean = emy + dy2/2
d is std
dev. = m(edy2 - 1) 0.5
M is the median =
emy
CV is coefficient of variation = (edy2 -
1)0.5
Cs is the coefficient of skewness =
3CV + CV3
When data are plotted on log-probability paper, a straight line occurs only for one value of Cs ( 1.139). Curved plots of data indicate the need to modify Cs. Figure 8.3 shows a plot of discharge versus probability. To widen the opportunity for fitting data to a defined distribution, more complex treatments of data have also been studied.
b. Log-Pearson Type III Distribution
This one of a series of distributions. The data are converted to logarithms and the mean is computed using equation 8.15 as a basis:
Mean 
xxxxxxxxxxxxxxxx (8.15)
The standard deviation is given by 
(8.16)
end the skew coefficient by
(8.17)
The value of X for any probability level is
computed from log x = log x + K·sd log x. (8.18)
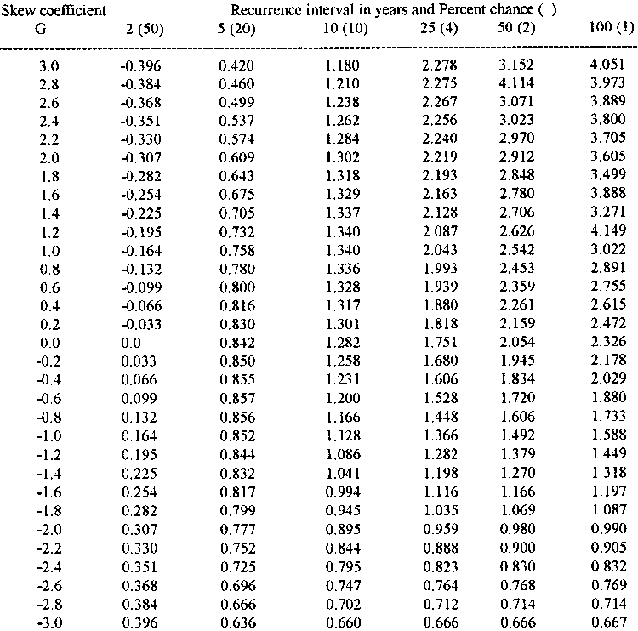
Table 8.3: Values of K for the
log-Pearson Type III Distribution
The Pearson Type III is a skew distribution, bounded on the left like many hydrological distributions. The skew parameter allows flexibility in fitting it to datasets and when the skew is 0, it is identical to the semi-log distributions used commonly in the past for hydrological analysis. Table 8.3 gives values for K for the log-Pearson Type III distribution which are used in the calculations of the worked example.
c. Gumbel (Extreme Value) Type I Distribution
The EV1 distribution, like the Pearson Type III, is one of a family of distributions, and its form parameter is equal to zero. As is explained in the Flood Studies Report (NERC, 1975), the distribution of maximum values selected from a data set approaches a limiting form when the size of the size of the data set increases. If the initial distributions within the dataset are exponential (see Peaks Over Thresholds, below), the Type I distribution results. The form of the distribution is given by:
p= 1 -e(-e)-y where (8.19)
p is the probability of a given peak being equalled or exceeded, e is the base of natural logs and y is a reduced (i.e. standardised) variate, a function of probability. Thus
x = 
+ (0.7997y - 0.45) sd x
(8.20)
In this case, the term in brackets in equation (8.20) is equal to the Pearson term K, that is the frequency factor K(Tr) is equal to - 0.45 + 0.779y (Tr).
Table 8.4 gives terms of the Gumbel distribution, for the calculation of flow probabilities.
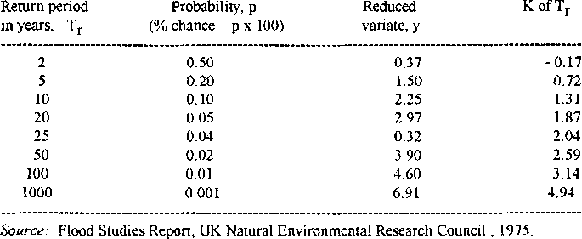
Table 8.4: Gumbel Type 1 (EV 1)
Distribution
Worked Examples
Pearson Type III Distribution:
A hypothetical set of log peak flow (=log q), annual maxima data from a small agricultural catchment when analysed, give the following values. Find the 5 and 25 year return period peak flows:
Mean of the logs of q, 
=
3.087
(not log of the mean)
Standard deviation
of the logs of q, sd log q = 0.981
Skewness coefficient G = 0.0390
The 5 and 25 year peak flow (q5) is found by the
following procedure:
From Table 8.3, K5 = 0.855 and K25
= 1.610
Therefore from equation 8.18, log q5 = 3.087 + (
0.981 × 0.855) = 3.926
q5 = antilog 3.926 = 8,429 1
s-1 (8.4 m³ s-1)
From equation 8.15, log
q25 = 3.087 + (0.981 × 1.610) = 4.666
q25 =
antilog 4.666 = 46,388 1 s-1 (46.9 m 3 s-1)
Gumbel (EV
1) Distribution
A set of hypothetical annual maxima data from a field catchment give the following values. Find the 10 and 100 year peak flows:
Mean peak flow, q = 1,234 1 s-1
Standard deviation
q = 434 1 s-1
From Table 8.4, K10 = 1.31 and K100 = 3.14
Therefore from equation 8.20 q10 = 1,234 + (1.31
× 434)=18031 s-1
and q100 = 1,234 + (3.14 ×
434) = 2597 1 s-1
8.1.5 Extreme Value Series
It has been found that in many cases, the whole set of data of hydrological events in a water year (that is the beginning of the wet or dry period of one year to the same time the next) need not necessarily be used in analysis. The largest or smallest values in a particular time period may be analysed instead, and often this time period is selected so that one flow per year is used; the Annual Series. The annual series is called the Annual Maximum Series where the largest flows are used or the Annual Minimum Series when lowest flows are analysed. As the time period increases, the data become less inter-dependent. In regions with discrete seasonal variations of flood, time periods of a few months may render the data independent and the annual maximum series is widely used.
Where a base level of flow is selected so that only floods which exceed this base are used for analysis, the data are said to form a Partial Duration Series. This type of series will be discussed below, but there is really little difference between it and the annual maximum series, except that the high level of the base in the latter excludes all flows but the greatest each year.
Annual Maximum Series (AMS)
The annual maximum series is a special case of the extreme value series and for return periods of 5 years or more it is often suitable, though the design of structures and the nature of a project will also influence whether the annual maximum series should be chosen. For instance a dam or bridge may not only be affected by the largest flood, but also by the second largest and other flows associated with a flood period. The annual maximum series takes no account of these other runoff events and therefore may not be suitable for use. Alternatively, a culvert may be washed away by the one large flow, but can easily and cheaply be repaired and the AMS may provide a suitable method of analysis. The annual minimum series may be used where low flows are under consideration.
In Table 8.5 the AMS is used to illustrate the estimation of size and probability of peak flows. The difficulties of small datasets may be acute when using the AMS, as only the single largest annual (or seasonal) peak is used in the ranking. The data may also be plotted on a log-probability graph with peak flow values on the log., y, axis. The form of the data is a straight line and this renders the extrapolation of higher return period flows, relatively simple.
The Flood Studies Report (1975) is a major work on flood probability analysis and recommends the following, alternative relations for the probability and return period terms in Table 8.5:
p = (m - 0.44 )/ (n + 0.12) and Tr = (n + 0.12)/ (m - 0.44) (8.21), (8.22)
These relations define "plotting positions" where p is the probability, m the rank of the flow, n the total number of items in the rank and Tr is the return period in years. Several such plotting position formulae have been tested (the examples shown in Table 8.5 are according to Weibull) and used. Those in equations 8.21 and 8.22, known as Gringorton's formulae, attribute longer return periods to higher floods in the series.
The difficulty experienced in using many methods to extrapolate from short spans of data is due to the estimation of the tail of the distribution from values not included in this tail. The annual maximum series is especially vulnerable to error since it discards most of the available data. The use of theoretical distributions, in particular when used in conjunction with partial duration series, are attempts to overcome these problems, though ultimately long periods of records are the best basis for probability estimates.
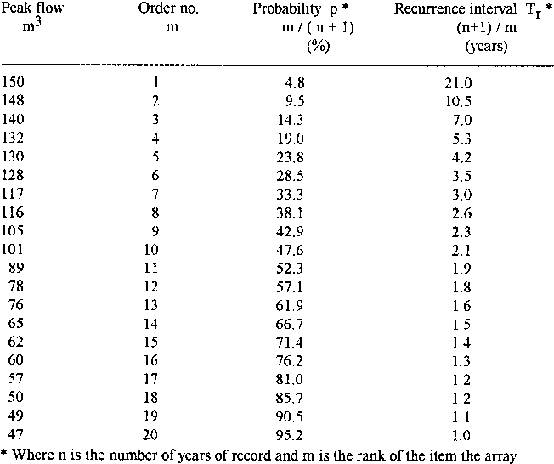
Table 8.5: Annual Maximum Peak Flows
8.1.6 The Problems of Short Records and Partial (Duration) Series
A partial series is made of all peak flows that exceed a selected threshold, the AMS being one particular case. In other instances, a number (usually from about two to five runoff events each year) are included, so that a larger range of data is selected from periods of short records. For this reason the partial series may also be known as the Peaks Over Threshold (POT) model. Although considerations have been made as to whether the exceedences should occur within a water year or a season, these considerations are less vital than the type of distribution of flood magnitudes, which influences the estimation of high return periods for given flows.
Several models have been studied, but the simplest is presented here. It assumes a random distribution of exceedences in any year or season and an exponential distribution of the magnitudes of these exceedences. These assumptions combine to give a Gumbel Type 1 distribution.
The problems of short records and the need to estimate flood flows for relatively small return periods is the situation usually faced by agrohydrological projects. The Flood Studies Report investigated the use of partial (duration) series to overcome the problem of short records and the work that it reports is of value, though the use of partial data is relatively well known.
a. Annual Exceedence Series (AES)
This series is a particular type of partial duration series, where the dataset is obtained by setting the level above which flows are included is such that the number of flows is equal to the number of years record. In real terms this means that some years will provide more than one flow, while some years will provide none at all. In this way, the occurrence of several high flows in one year will be taken into account, unlike the annual maximum series. The relations between these two series (and indeed the annual maximum and partial duration series in general) are discussed below. In the example above on the suitability of series selection and the destruction of bridges, dams and culverts, the place of the annual exceedence series can be seen.
b. Peaks Over Threshold Model
For very short return periods (Tr), values obtained from the annual maximum series and the POT model differ appreciably, when longer periods are considered, they are very similar. However, the basic question as to which is the most suitable method of estimation to use, is still open to question. For example, the annual maximum series, by limiting exceedences to one peak per year, may actually bias the sampling distributions by not taking into account, say the second or third largest flood on record. On the other hand, the POT model is often seen to work better for small return periods when only one exceedence a year is used. For longer return periods, a greater number of exceedences a year seem more suitable. Below is a list of ratios of return periods for the POT and annual maximum series:
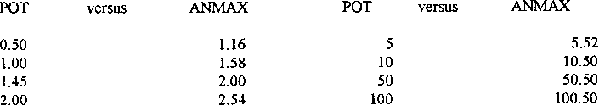
Table 8.6: Return Period
(Tr) POT versus Annual Maximum Series Return Period (years):
The simplest manner in which to abstract the data from the full set is to decide upon a number of flows per season to be analysed which exceed an (as yet) unknown threshold and from the relations given below, calculate the threshold.
The formula that gives return period flow is:
Q(T) = q0 + B (ln $ + ln T) (8.23)
Q = the peak flow of return period T
q0 = the threshold value
B = the gradient of the distribution
$ = the number of exceedences
The sample size is noted as M, the minimum flow of the sample is qmin, and the mean is q.
The linking equations of the parameters are:
q0 = qmin - (B/M) and (8.24)
B = M ( q
- qmin) / (M - 1) (8.25)
The sampling variance, var. QT is given by:
var. QT = B2/N [(1- ln $ -ln T )2 / N$ -1] + (ln $ + In T)2 where (8.26)
N = the number of years of record. The procedure for using the POT model is shown below, by worked example.
Worked Example of the POT Model
As stated earlier, the assumption is made that the magnitudes of the peaks are distributed exponentially, however in some instances this may not be the case, therefore the first step in approaching the use of the POT model is to verify this exponential assumption. The data in Table 8.7 were obtained from a 4,000 m² rangeland runoff plot with a land slope of about 2%, sandy loam soil and a vegetation cover in the range 55-65%. It is important to note that no major changes in the catchment characteristics took place during the period of record.
From the total set of peak flow data, a number of the highest flows are selected, such that M, the total number of peaks selected = $ (exceedences per year) × N (the number of years of data). For this example $ = 3 and $ = 5 exceedences per year were used to illustrate by result, any variation due to the use of different exceedences. They were abstracted from data collected over only 3 years.
Thus, a total of 9 and 15 peaks were used in each case, though there is no statistical evidence to suggest that a better result is obtained from using a larger numbers of exceedences. It is important to note that like the annual exceedence series, no regard is given to whether or not the peaks occur in any particular year, it could be possible, but unlikely, that all data were drawn from the same year.
The values of the reduced variate y are calculated from:

xxxxxxxxxxxxxxxxx (8.27)
such that when N, the number of years from which the data are drawn = 5, then:
y1 = 1/5 = 0.200; y2 = 1/5 + 1/4 = 0.450.........y5 = 1/5 + 1/4 + 1/3 + 1/2 + 1/1 = 2.283, etc.
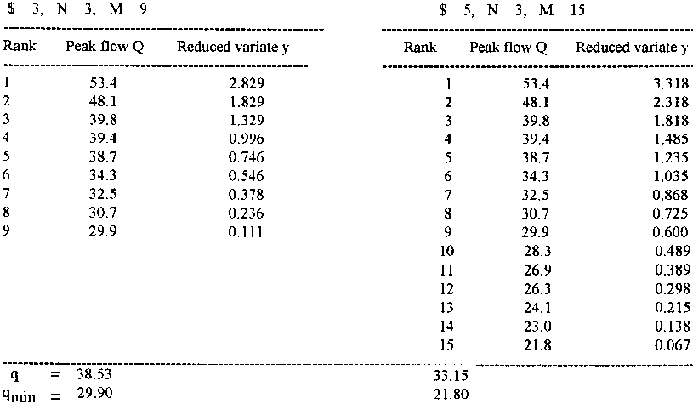
Table 8.7: Data for POT Model,
Exceedences 3 and 5 per Year
The peak flows in litres per second and variate y are plotted as in Figure 8.4, both distributions appear closely exponential.
The calculation of Q10 and Q25 peak flows for $ 3 and $ 5 are shown below.
|
For $ 3 and using equation 8.25 |
For $ 5 and using equation 8.25. |
|
B = 9 (38.53 - 29.90) / 8 = 10.83 |
B = 15 (33.15 - 21.80) / 14 = 12.16 |
|
Using equation 8.24, |
Using equation 8.21, |
|
q0 = 299-(1083/9) = 28.70 |
q0 = 21.80-(12.16/ 15) = 20.99 |
Using equation 8.23, the 10 and 25 year peak flows are:
|
Q10 = 28.70 + 10.83 (ln 3 + ln 10) = 65.5 l s |
1Q10 = 21.80 + 12.16 (ln 5 + ln 10) = 69.4 l s |
|
Q25 = 28.70 + 10.83 (ln 3 + ln 25) = 75.5 l s |
1Q25 = 21.80 + 12.16 (ln 5 + ln 25) = 80.5 l s |
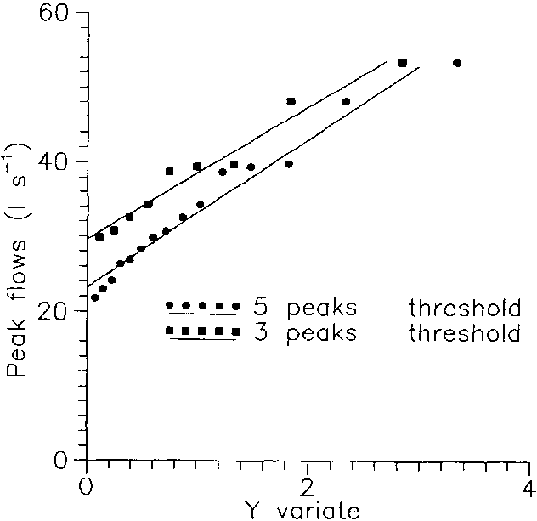
Figure 8.4: Plot of Peak Flow Q
versus Reduced Variate y
Stochastic Analysis
The term "stochastic" is frequently met with in hydrology and although the term is used in statistics to define the data as being governed by the laws of chance (synonymous with terms such as "random" or "probabilistic") in hydrology "stochastic" refers to time series that are partially random and may be regarded as a treatment of data halfway between probability analysis and deterministic modelling.
Although the occurrence of events is regarded as being random, the order in which the events occur is regarded as carrying significance, unlike probability analysis which is concerned only with size and number of events. Stochastic hydrology is useful for design and decision-making in hydrology, since it is assumed that although future runoff events are not known, they will have the same statistical properties as historical records. Stochastic methods tend to deal with cycles of events and the generation of possible future flows. It is assumed that the statistical properties of runoff do not change with time. Two approaches are used; either data are aggregated from monthly data and combined to give annual results or seasonal/annual data are disaggregated to provide monthly flow values.
The general form of the stochastic modelling equation on a monthly basis is:
Xi + 1 = Xj + 1 + Bj ( X1 - Xj ) + Ti Sj + 1 (1- Rj2)0.5 where
Xi + 1, Xi = generated flows during the (i + 1)th and ith months
Xj + 1, Xj = mean flows during the (j + 1)th and jth months
Bj = least squares regression coefficient based on Bj = RjSj + 1/ Sj
Ti = normal random variate with mean zero and variance one
Sj +1, Sj = standard deviations of flow during the (j+1)th and jth months
Rj = correlation coefficient between jt and (j+1)th months
Although stochastic analysis is especially widely used in generating long sets of records from shorter periods, the amount of information needed for such complex analysis is nevertheless considerable. Annual flow volumes, or even monthly results are often of little value to water harvesting and agrohydrology in arid and semi-arid areas, though stochastic analysis is often used when reservoir inflows are under study.
8.2.1 Runoff Analysis
The Runoff hydrograph
In humid regions, runoff is composed of contributions from groundwater and, when it rains heavily, surface flow. Groundwater enters the stream channel when the water table adjacent to a stream is at a higher elevation than the surface of the stream and a slow, but continual seepage occurs. In arid and semi-arid areas, where the ground water table is usually very deep, the opportunity for seepage is rare and stream flow is usually the concentration of runoff coming directly from the land surface. In some cases however, even in relatively arid areas, sufficient water from the high stages of river flow may enter riparian deposits and be released slowly from this temporary storage to extend river discharge beyond that supported by direct, surface contributions. In the case of small runoff plots and field sized catchments, where stream channels are not found, runoff is composed only of surface flow.
Where ground water and surface flow are combined, their separation by use of the flow hydrograph is a routine, but important step in analysis. Where there is no groundwater contribution, the whole flow volume is attributed to surface flow. A great deal of research has been undertaken to define different hydrograph types and what they represent in terms of the runoff process, rainfall, the variability of source areas, etc. Figure 8.5 shows a simple diagrammatic representation of a runoff event, the flow hydrograph, and defines its components. Alternative methods of separating ground water and surface flow are shown, though to some extent each is arbitrary. If the hydrograph is plotted with a logarithmic y axis, the curve usually breaks into three sections, each section represented by a straight line component of the whole. Conventionally, these are regarded as the contributions from groundwater, interflow (sub-surface but not deep) and surface flow, though this probably is a rather simplified view of true conditions.
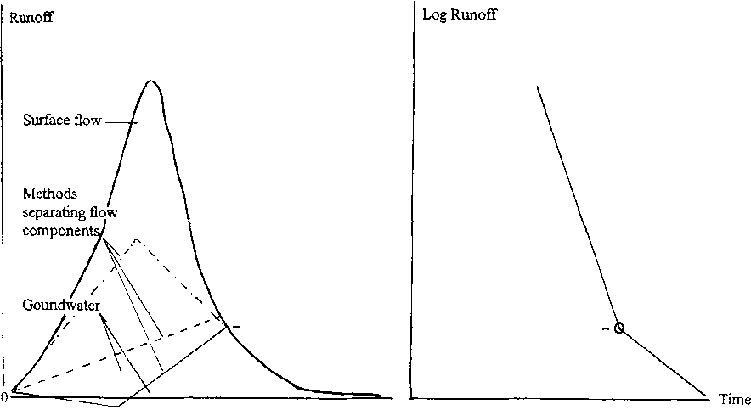
Figure 8.5: The Flow Hydrograph and
Its Components
Unit Hydrographs
Despite the variation in runoff due to the complexity of catchment characteristics and rainfall amounts, intensities and distributions, the Unit Hydrograph method of synthesising runoff hydrographs for particular rainfall amounts is widely used. By constructing a basic runoff hydrograph from a known and conveniently selected rainfall amount, runoff hydrographs can be synthesised for any rainfall amount. The method is not appropriate for small runoff plots or very small catchments less than about 2 hectares in area.
The unit hydrograph is defined as the surface runoff hydrograph generated from a unit depth of rainfall distributed over the catchment area, occurring during a specified period of time. The most suitable period of time will depend on the typical flow duration and size of catchment. The unit hydrograph is best obtained from a storm of reasonably uniform intensity (and therefore usually of short duration), desired duration and large volume. A single storm peak is preferred, but is not essential. The unit hydrograph ceases to be applicable when the catchment area is so large that it is not covered by a single storm, and in such circumstances the catchment must be divided into subcatchments that are treated separately.
Usually several unit hydrographs are obtained from a number of storms and combined, to "average" the effect of different rainfall patterns.
Figures 8.6 and 8.7 illustrate the method of unit hydrograph separation from a single storm. The first step is to separate the base flow component from direct (surface) runoff. The volume of direct runoff is calculated, for example in m³ and then converted into runoff depth, i.e. the depth of runoff if the volume were to be spread evenly over the catchment, for example in cm. The ordinates of the direct flow hydrograph are divided by this runoff depth, which then defines the unit hydrograph for 1 cm of direct runoff.
The average unit hydrograph, which gives a more generalised hydrograph shape and size, is drawn as an interpolation to conform to the overall shapes of several individual unit hydrographs, using the average peak flow and average time to peak as guides to the outline of the graph. It should not be surprising that the unit hydrograph may not show precise linearity when used to construct flows for a wide range of volumes, since the recession of flow depends, to some extent, on peak flow. However, estimates of flow can be good, and the unit hydrograph can be regarded as the typical hydrographic form of a particular catchment. Figure 8.8 shows the use of the unit hydrograph in construction of the hydrograph from a complex rainstorm.
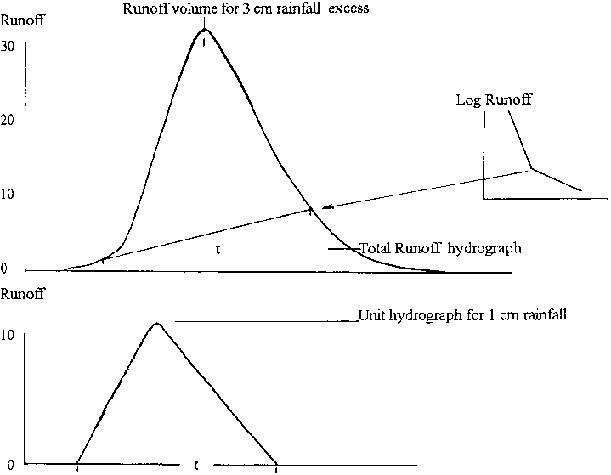
Figures 8.6 and 8.7 Derivation of a
Unit Hydrograph
Conversions to other unit hydrograph duration periods can be made, where these are integral multiples of the basic unit hydrograph, by simple superimposition of a series of the unit hydrographs.
Where time periods are not whole multiples of the unit hydrograph time period, S-hydrograph techniques can be used. These techniques provide a flexible method of obtaining a wide range of hydrographs for different durations, but they are complex and time-consuming. Although they are in widespread use and are important in the understanding of orthodox river behaviour, they are marginal to agrohydrological research and water harvesting applications. The selection of a unit hydrograph that will allow a convenient permutation of durations is not usually difficult to achieve. Most textbooks on hydrology cover the subject in detail. An Instantaneous Unit Hydrograph, which is independent of duration, can also be derived.
Various empirical formulae have been developed to enable a Synthetic Unit Hydrograph to be defined. These have related catchment characteristics to hydrograph form, but the application of these empirical formulae to define a synthetic unit hydrograph tends to be of limited value. If unit hydrographs are desired for ungauged streams, it is preferable to obtain them by the use of flow data from adjacent catchments. The theoretical bases of these variations of unit hydrograph theory may be addressed by reference to a standard hydrological textbook such as the Handbook of Applied Hydrology; see chapter 1.
A flow hydrograph provides two especially important values: the runoff volume and the peak flow, but in most cases interest will also be taken in the duration of the rising and falling limbs; the time after rainfall starts that runoff
begins and the overall duration of flow. For the practice of water harvesting these characteristics of flow have practical implications and are important in understanding when peak flows have passed; when flow diversions should be made; whether a recession flow will continue or rapidly decline, whether all flow is direct or whether sub-surface contributions can be relied upon to deliver further opportunities to supplement the water availability to crops.
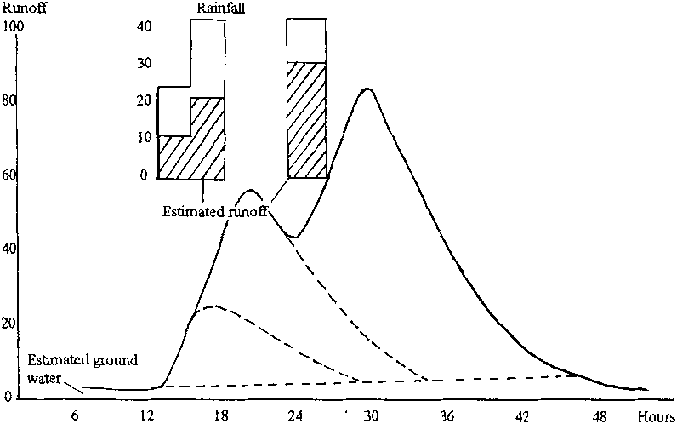
Figure 8.8: Construction of a Flow
Hydrograph using the Unit Hydrograph
The construction of water harvesting and field systems assumes that sufficient quantities of runoff water will be available to be moved safely to crops, using well designed structures that can control and manipulate specified peak flows. The study of runoff volume data in agrohydrology anticipates these activities by trying to answer two main questions. The first and most important is, will the amount of runoff that can be collected be agriculturally useful? The agricultural dimension is very important and "useful" will be determined by geographical location and agricultural practice; crop type and climate. However, the clear presentation of simple hydrological analyses will allow this question to be answered according to the conditions that prevail in a particular locality.
The second question, which factors most control the production of runoff and how? is concerned with an understanding of the runoff process. The quantification of the relationships between the components of these physical processes is important, so that predictions of future behaviour can be made. The analysis of rainfall and catchment information is essential to the study of runoff volumes.
8.2.2 Rainfall Analysis
The analysis of rainfall information may use the statistical distributions and probability procedures that have been discussed previously in this chapter. Regression analysis is important in understanding how rainfall amounts and intensities affect the production of runoff. These characteristics of rainfall may also be used in multiple regression in association with other influential factors. In addition, treatment of basic rainfall data to render them useful for a variety of applications is an important stage of analysis. The analysis of rainfall information concerns two types of data; those obtained from a single point and those extrapolated or interpolated from a number of points to estimate rainfall over an area. These data may involve a single event or may be directed at the study of how precipitation changes with time.
General Characteristics of Rainfall
Arid and semi arid regions, where water harvesting is likely to be practiced, tend to experience great spatial variability of rainfall; rainfall intensities also tend to be highest during the first half of a storm. It has been found that the characteristics of rainfall in these areas is essentially independent of locality and may be similar in widely different geographical regions. The standard deviation from the long term mean in such areas is very high, the average annual rainfall varying between by perhaps 35% to 200% of the mean, compared to temperate climates where standard deviations are more typically only 10 - 20%.
Missing Data and the Adjustment of Records
Individual Data Points
Missing point rainfall data are not uncommon and may be estimated in three ways, each of which use information that is taken from stations close to that which has no record. The three alternative methods of estimation are:
Averaging the same daily values from three adjacent stations; Estimating from an isohyetal reconstruction of the missing day's rainfall Using a weighted ratio.
In the first case, the simple arithmetic average may not provide an accurate result where, for example, topographic variation is great and where rainfall values are influenced by such variation. However, if the annual rainfall totals of the adjacent stations are within 10 % of the station with missing data, this method is regarded as suitable.
An isohyetal estimate of a station's missing rainfall is easy to achieve where an adequate density of stations allows it and where the spatial variability of rainfall is low. Knowledge of local conditions can provide added accuracy to such estimates and the technique of isohyetal construction is described below.
In some areas, the spatial variability of rainfall and/or an insufficient number of rainfall stations may preclude the production of an isohyetal map, in which case the latter of the three options is to be preferred. The missing value may be obtained from an equation linking the rainfall experienced by adjacent stations:
Dm (missing daily rainfall) = 0.333 [D1 (Anm/ An1) + D2 (Anm/ An2) + D3 (Anm/An3)] (8.28)
where:
D is the daily rainfall
An is the annual total rainfall
the subscripts 1, 2, and 3 refer to the adjacent stations and m to the station with missing daily data.
Adjustment of records
The change in location or exposure of a raingauge can effect long-term records. The Double Mass Curve technique may be used to correct such defective records, by the comparison of data from the queried station with those from adjacent gauges. Two important considerations should be taken into account; that records from at least ten stations are needed by which to make a comparison; and the longer and more homogeneous the records of these stations, the more successful the correction.
In the case of example Figure 8.9, the values of the queried station must be corrected downwards by a factor of 1357/1535 = 0.89, after 1987.
Maximum accuracy is gained by the comparison of double mass data within the base stations' dataset and the elimination from the set of any that show large changes of slope. Minor differences can be ignored, or more than one parallel slope line can be used to account for true differences. The method is not recommended for daily or individual storm values.
This method is frequently used in the same way to compare and correct the flow records of stream gauging stations.
Accumulated Annual Rainfall of Queried Station (mm)
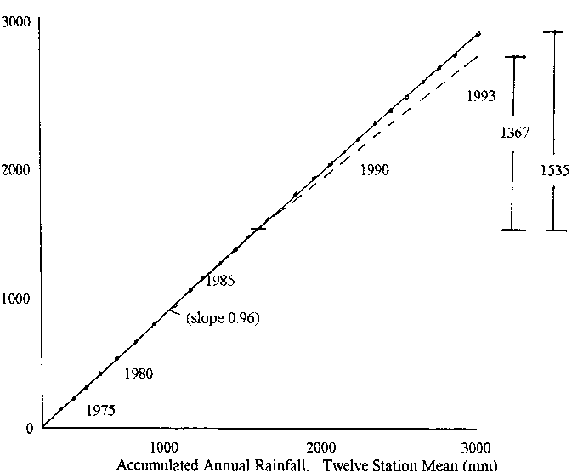
Figure 8.9: Double Mass Comparison of
Rainfall
Rainfall Depth Over Areas from Point Measurements
The point measurement of rainfall at a site is usually adequate to describe rainfall on an area basis when small catchments and runoff plots are used, though the high spatial variability of some locations can be extreme. As catchment area increases, especially in those regions with a large inherent spatial variation of rainfall, it becomes increasingly important to convert rainfall data collected at several points into a rainfall depth over the area.
Several methods can be used to extend rainfall depths at points to areas. The arithmetic mean of several stations can be used, but this usually encounters limitations of spatial distribution and does not weight any variation in network densities. The Thiessen Polygon and isohyetal methods are the two commonly used alternatives to the arithmetic mean and are described below. The Thiessen Polygon method assumes that values of rainfall amounts at a point can be extended half way to the next station. Polygons are constructed around each station and the area of each polygon is then used to weight the rainfall value at the centre of each . The geometrical construction of this method is illustrated in Figure 8.10 as is the area-based weighting applied to the value of rainfall at each station.
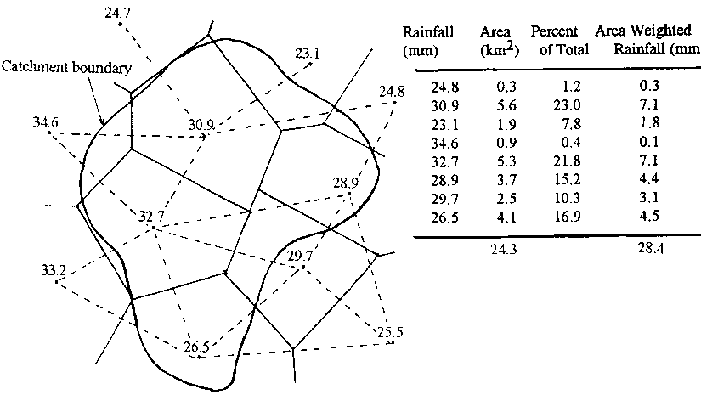
Figure 8.10: Thiesson Polygon Method
to Calculate Rainfall Over an Area (Daily Rainfall)
One disadvantage of this method is that the polygons must be re drawn each time data from a station is missing, or if a station is removed from the network. Figure 8.11 illustrates the method of isohyetal construction.
The Isohyetal Method uses station data to construct isohyets of equal rainfall. Interpolations between station values are made according to knowledge of topography and climatic regime. The average rainfall depth is then calculated by adding the incremental volume between adjacent pairs of isohyets weighted by area as in Figure 8.11. This method has the advantage that calculations are made according to knowledge of the climate and topography of a catchment. Unlike the Thiesson method which relies solely on geometric construction, variation in rainfall amount will reflect changes in altitude and proximity to other meteorological influences.
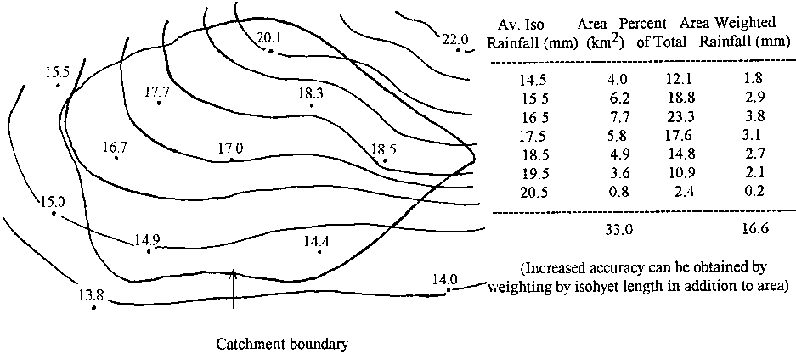
Figure 8.11: Isoheyetal Method
Depth -Area -Duration Analysis
DAD analysis is used to determine the greatest precipitation over different areas and for different durations. Regional and seasonal comparisons can be made, though the analysis is only applied to storms that are expected to approach maximum values. Several centres within a storm may have the greatest DAD values and these can be compared to identify the greatest for various selected areas and durations. The procedure is often used, but is relatively complex and will be of limited value in many water harvesting situations unless large catchments are under study. The procedure is therefore outlined briefly. Depth-area-duration data may be available from local Meteorological services.
Conversion of the 24 hour ("daily") rainfall to a time period more suitable to hydrological purposes is needed, often the 6 hour rainfall amount, so that aggregation into various time periods of, for example, 6, 12, 18, 24 hours, etc., is possible. Comprehensive recorded rainfall data for the storm are needed. Mass curves of rainfall are drawn (accumulated rainfall versus time). Several total storm depth are curves are then prepared by dividing the total storm rainfall map into major centres, where there are more than one, and determining the total size of the area and the average rainfall depth within the area which is enclosed by successive isohyets around each centre.
A time breakdown is then needed for these depth-area curves by weighting the rainfall of each station by the ratio of its Thiessen area within the isohyets, to the total area within the isohyets. A time distribution of the total storm rainfall within each isohyet is found. Values are plotted as area versus total rainfall, with different lines for different durations. Smaller areas receive largest rainfall amounts for a given duration, and rainfall amounts generally increase with duration, but regional differences can be very great.
Areal Reduction Factor (ARF)
Rainfall depth tends to decrease as area increases. In many instances, this reduction cannot be assessed by the use of a comprehensive network of raingauges, because such a network does not exist. A simple factor that can be applied to point rainfall for a specified duration and return period, and which converts point rainfall to areal rainfall is called an areal reduction factor (ARF). Research has shown that such a factor, for a specified area and duration, does not vary greatly with return period and this aspect can be ignored for practical purposes.
A simple ARF can be obtained by selecting the maximum areal rainfall event for a catchment. The rainfalls (R1) at each station are noted. In some cases these will be the same as the maximum annual rainfall event (R2 for a specified or desired duration, D), but in others they will not. The ratios of R1/R2 are noted and mapped for each year and an areal mean of R1/R2 is found. The mean of a number of years' means is then calculated and this gives the ARF for a known area A and duration D.
In many cases, comprehensive rainfall records will not be available to allow areal estimates of the mean ARF by mapping, but the method is adaptable to the circumstances most commonly found in developing countries: medium term (> 10 years) daily rainfall records from a limited number of stations. In general it is better to analyse local data in a simple way than import relations obtained from other world regions. A straightforward adaptation of the method described above, to obtain an ARF, is illustrated below by an example. The data originally used for the adaptation came from Belize, in Central America.
The 1 day rainfall with a 5 year return period was selected as desirable for the following reasons: the 1 day rainfall is commonly available, it is suitable for use since the 1 day and runoff-producing storm rainfall are often very similar, and they can be regressed and their precise relation determined; the 5 year return period is one widely applicable to farm practice, though the 10 year return could also be justified. Eleven rainfall stations (maximum station data 22 years) were used in the analysis, over an area of approximately 2000 km².
According to their long term average annual rainfall, the rainfall stations were divided into three groups, each located within one of three AAR bands of 1400 - 2000 mm, 2000 - 2800 mm and > 2800 mm per year. This information was obtained from isohyetal maps. The R1 and R2 values were listed for each station and year, and the ratios of R1/R2 were obtained. The arithmetical average of the ratios was then calculated for each station. The overall average ARF for each rainfall band was then obtained from the stations within it, by weighting according to the length of station records.
The area-reduced, 1 day 5 year point rainfall for each station was then found by listing daily rainfall in an annual maximum series and applying the appropriate band ARF. These then gave an average, area reduced value of the 1 day, 5 year rainfall for the catchments under study, the contribution from each station being weighted according to area as defined by the Thiesson method. Where a catchment was composed of areas lying within different isohyetal bands, the different ARFs were applied, also by weighting in proportion to area.
Rainfall Depth and Intensity - Frequency Relations
Where sufficient records exist, the relations between rainfall intensity or total rainfall amount, duration and return period are often established, for use in practical applications concerning runoff, such as the theoretical calculation of peak flow values. One of two methods are usually applied, but reasonably long-term intensity gauge records are needed for both.
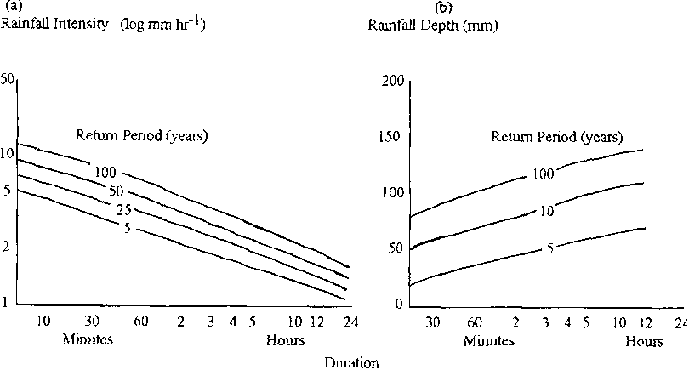
Figures 8.12 (a) and (b) Rainfall
Intensity-Duration and Depth-Duration Frequency Graphs
In the first method a particular time interval is selected for convenience; the 5, 10 or 15 minute interval is often used, and the maximum depths and mean intensities are calculated for this time interval. Generally, mean intensities will be highly variable within the time period and will become less hydrologically significant as the time period increases. In the second method, the highest rainfall intensity for any duration is the criterion for interpretation. Rainfall depth by segments of the intensity trace are classified to determine hydrological response. Typical relations for return period intensity and duration for a particular station are illustrated in Figures 8.12 (a) and (b). Locations with similar relations may be mapped where there is sufficient information.
Theoretical Distributions
Rainfall data may be analysed according to the methods which apply theoretical statistical (usually Extreme Value) distributions to the data, as discussed in section 8.1 using runoff data. Return periods and probabilities for different rainfall amounts can be obtained. The Pearson Type III distribution (with varying skewness coefficients) has been found to fit semi-arid data to a satisfactory extent in many cases. The validity of different distributions may be compared or tested using the Chi-square test, described in section 8.1.
Unlike temperate climates which usually have a normal distribution, rainfall distributions in semi arid regions tend to be positively skewed, that is they have many more rainfalls smaller than the mean, than greater than the mean. The mode is less than the value exceeded in 50% of years (the median) and the mode and median are less than the mean. The mean is of limited use in describing the central tendency of data in these areas and the mode is often used as the statistic to describe the most frequently experienced conditions best. Associated with the skewness of such data is the difficulty in obtaining estimates of mean rainfall without large errors, especially from short records.
The annual maximum series and partial duration series are also used to evaluate extreme rainfalls and their probabilities by ranking and the imposition of selected thresholds.
Alternatively, the probability of daily rainfall amounts may be studied by grouping rainfall according to amount, for example rainfalls greater than 1 mm, 5 mm, 100 mm etc. and calculating their probabilities. Table 8.8 below gives an example.
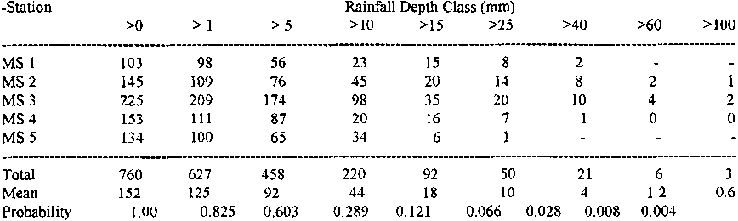
Table 8.8: Probability Distribution
of Daily Rainfall Occurrences
Bi-modal distributions of rainfall (two main peaks in the rainfall season) are also often evident, due to different meteorological conditions that prevail. In these circumstances it may be necessary to study rainfall statistics on a short period basis, so that the parent population of rainfall events accounts for this bi-modality.
8.2.3 Evaporation and Evapotranspiration
The use of evaporation and evapotranspiration data is important to runoff and agricultural studies. The rate at which runoff is produced will often depend on the existing wetness of the soil, which in turn is highly inversely correlated to evaporation and evapotranspiration losses. Plant growth is intimately bound to soil moisture availability and the stage and rate of crop growth will be affected as well as be influenced by evapotranspiration
8.2.3.1 Free Surface Evaporation
Evaporation is most commonly measured for agricultural purposes using evaporation pans (chapter 4) and the US.
Weather Bureau 'A' pan is now the world international reference pan type. Although other pan designs are met with, most organisations use 'A' pans and methods of estimating evaporation in the following section concern this type of pan.
The evaporation (E0) from a free surface is impossible to measure when surface areas are very large; however coefficients which quantify the relations between evaporation losses from 'A' pan data and water bodies have been arrived at. These vary according to location and seasonal and short-term changes in weather. They can be used to obtain evaporation estimates from streams and other water bodies. For example if 'A' pan losses are 2 mm day-1 and the evaporation coefficient is 0.70, the daily free surface evaporation from a distribution channel 2 km long and 5 m wide will be:
fdse = E0 = 2000 × 5 × 0.002 × 0.70 = 14 m³ day-1
Losses from seepage, percolation etc., are not accounted for. In a similar way, reservoir storage losses can be estimated, usually by using monthly values of the pan coefficient.
The measurement of climatic variables is essential in establishing pan coefficients, and in most countries some information on these coefficients will be available. Temperature, wind speed and duration, barometric pressure and the nature of the container all effect evaporation measurements to various degrees. Table 8.9 gives some examples of long-term annual 'A' pan coefficients and examples of seasonal variation at Khartoum (Sudan) and Lake Hefner (USA).

Table 8.9: Example 'A' Pan
Coefficients
Empirical Formulae
Many empirical formulae have been developed to estimate evaporation, based on Dalton's Law; the basic driving mechanism of these equations is the difference in vapour pressure between water and the atmosphere. The greatest problem with empirical formulae is the difficulty in measuring the components of the equations in a manner that can be related realistically to the dynamic processes that lead to evaporation.
Dalton's equation is E = C ( es - ed) where (8.29)
E is the rate of evaporation
C is a constant
es is saturated vapour pressure at the temperature of the water surface in mm of Hg.
ed is actual vapour pressure of the air (es × relative humidity) in mm of Hg.
The constant C in equation 8.29 has been described as:
C = (0.44 +0.073 W) (1.465 -0.00073p) where (8.30)
W is wind speed in km hr-1 at 0.15 m
p is atmospheric pressure in mm of Hg at 0°C.
E is in mm day-1 and reservoir evaporation = E × 0.77
Alternatively, the constant C for shallow ponds and evaporation pans has been evaluated as:
C = 15 + 0.93 W (8.31)
and for small lakes and reservoirs as:
C = 11 + 0.68W (8.32)
with W as for equation 8.30.
The Water Balance method of estimating evaporation from reservoirs, compares changes in storage with a balance of known in flow and out flow. This method appears to be simple, but seepage losses are extremely difficult to calculate or measure accurately. Precipitation onto the reservoir can also be a complicating factor. Energy Balance methods are analogous to water in flow and out flow, balancing all the energy components in the evaporation process. However, although they have been tested more rigorously in recent years, difficulties still remain with instrumentation and their use is not widespread.
Evaporation from Soil Surfaces
The evaporation of water from soil surfaces is a more complex process than that from a free water surface. Although during periods of saturation, these processes may be very similar, saturated conditions rarely last for long and the evaporation rate drops rapidly as soil moisture levels decrease; evaporation from soils at less than field capacity may even be regarded as generally unimportant. Soil evaporation losses are defined by free energy and the free energy required by plants to take water at wilting point is less than 0. 1% more than at saturation. In addition, evaporation from soils depends on the nature of the soil; its texture, chemistry, organic content, vegetation cover and depth. The losses from soils and vegetation are usually combined and treated as one process, termed evapotranspiration, though in regions where vegetation cover approaches zero or plants become dormant at certain seasons of the year, it may be desirable to monitor evaporative losses of soil moisture.
8.2.3.2 Evapotranspiration
Transpiration is the process whereby plants lose water from their leaf stomata and is essentially the same as evaporation, though not from a free water surface. Losses are proportional to the diameter of the stomata, but not their area, as is true for a perforated membrane. The rate of transpiration is essentially governed by the difference between vapour pressure under the stomata and that of the atmosphere, the number of stomata per unit area being variable with species and climatic conditions. Evapotranspiration (Et), sometimes called 'consumptive use', is the evaporation of water from all sources combined. The term 'potential evapotranspiration' (Ep) defines conditions where water availability is in no way limiting. 'Actual evapotranspiration' (Ea) attempts to define realistic conditions, whereby rates fluctuate according to the availability of water and changes in climatic conditions.
Evaporation Pans
Because the soil water availability conditions that allow potential evapotranspiration are not often met with, empirical studies have attempted to relate 'A' pan evaporation values to actual evapotranspiration values. Such relations should be used with caution, though most experimental data show them in the form:
Crop (Actual) Evapotranspiration Ea = k E0 (Pan Evaporation.) (8.33)
where k is a coefficient according to crop and stage of growing season.
Table 8.10 gives values of k for a variety of crops during different stages of growth. Values take some account of incomplete shading, but crop density, soil variability, wind profile etc., can make significant differences and values should be only regarded as a guide.
Table 8.10: Coefficient k to be
Multiplied by 'A' Pan Evaporation to give Actual Evapotranspiration
Empirical Formulae
A wide range of empirical formulae have been developed to calculate evapotranspiration. The most commonly used are discussed below.
a. Blaney-Criddle Equation
This relatively simple equation estimates consumptive use when water availability is not a limiting factor. Like many of the empirical equations for evapotranspiration it is most suitable for conditions immediately after rainfall, irrigated conditions or as a climatic descriptor:
Monthly Ep (in inches) = kF where (8.34)
F=(t × p)/100
k is the annual, seasonal or monthly consumptive use coefficient (for different crops)
p is the monthly % of daytime hours of the year, occurring during the period
t is the mean monthly temperature in °F
The greatest difficulty in applying the equation is the determination of the crop factor 'k', which varies not only with crop type, but also with climate and growing season. Examples are given below in Table 8.11, which relate to specified crop growing season lengths.
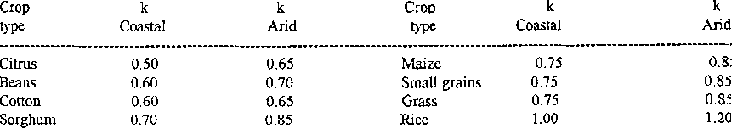
Table 8.11: Crop Coefficients (k) for
the Blaney- Criddle Equation
Table 8.12 gives daytime hours percentages for various latitudes.
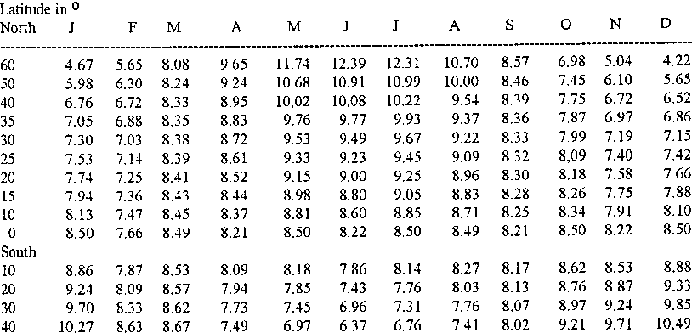
Table 8.12: Daytime Hours Percentages
( 100 p) for the Blaney-Criddle Equation
Thornthwaite Equation
This equation is based on an exponential relation between monthly mean temperature and mean monthly consumptive use, based on experience gained in the central and eastern states of the USA. It is widely-applied, but tends to be less satisfactory in regions that undergo frequent short-term changes in temperature and relative humidity.
Monthly Ep in mm = 16(10t/I)a where (8.35)
t is the mean montthly temperature °CI is a temperature efficiency index (and is equal to the sum of 12 monthly values of the heat index 'i' which= (t/5)
1514 for each month of the year and where t is the mean monthly temperature in ° C).
a is a cubic function of the annual heat index ' I ', which can be obtained from Table 8.13 or from
a = 6.75 × 10-7 I3 - 7.71 × 10-5 I2 + 1.792 × 10-2 I + 0.49239 (8.36)
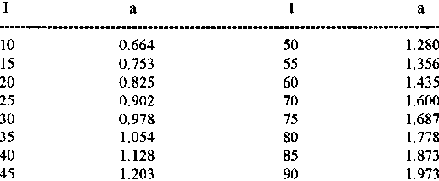
Table 8.13: Values of 'a' in the
Thornthwaite Equation
It is necessary to adjust the calculated rates of evapotranspiration, because monthly durations are not equal and the number of hours of evaporation in a day will vary with latitude and season. The adjustment factors are given in Table 8.14.

Table 8.14: Adjustment Factors for
Thornthwaite Values of Ep
Penman Equation
Penman's equation is the most complete theoretical approach to estimating potential evapotranspiration. The collection of data for many of the meteorological variables described in chapter 4 is directly attributable to the application of this equation. The equation is probably the most widely used empirical formula and shows that the consumptive use of water is inseparable from the level of incoming solar energy. In effect, the Penman equation is a combination of a measure of the drying power of the air and an estimate of available net radiation.
Penman's Equation is of the general form:
Ep in mm day -1 = [D / d (Rn) + Ea]/[(De/d) + 1] where (8.37)
D is the slope of the saturated vapour pressure curve / temperature curve at mean air temperature in mm Hg °C-1
Rn is the net solar radiation [Ri (1 - r) - Rb] whereRi is the radiation reaching the earth's surface in cals cm-2 min-1 and is = Rs (a + bn/ N) where
Rs is incoming radiation in terms of mm of water evaporated day-1, 'a' and 'b' are latitude constants
N is the maximum possible duration of bright sunshine in hours, at the location
r is the reflectance (albedo) of the surface which is a ratio of reflected radiation / incident radiation
Rb is the long wave back radiation
d is the psychometric constant, 0.49 mm Hg ° C-1 or 0.66 mb ° C-1
Ea is the mass transfer (Dalton's equation component) and is = f (u) (es - e) where
f(u) is a function of wind speed in m s-1
es is the saturated vapour pressure at air temperature at the evaporating surface in millibars
e is the vapour pressure of the atmosphere above in millibars
Penman's equation has been modified for various conditions and locations of latitude, with different values for the various numerical factors included in the equation. The example of Penman's modified equation below is given with constants according to a geographical location in the central USA, with constants and variables for °C, potential evapotranspiration is in mm day-1.
Ep = D / D + d[Rs (1-r) (0.22+0.55( n/N))0 - D /D + d [d Ta4 (0.56-0.091ed1/2) (0.10+0.90 (n/N))] + d/D + d[(0.175+0.0035 u) (ea- ed)] (8.38)
(This equation is in wide use elsewhere, with only minor modifications of the numerical constants given above.) where,
Ep, d, D, r and N are as above in equation 8.37n is the actual number of sunshine hours recorded
Rs is radiation at the top of the atmosphere and relates to time of year and latitude
d is the Stefan-Boltzman constant, 2.01 × 10 9
Ta4 is black body radiation at mean air temperature (= mean daily air temperature + 273 °K in mm of evaporation)
u is the wind run at 2m in km day-1
ea is saturation vapour pressure at mean daily temperature (millibars)
ed is mean vapour pressure (millibars)
Table 8.15 Coefficients a and b
|
Latitude (° N and S) |
a |
b |
|
54 |
0.21 |
0.55 |
|
36 |
0.23 |
0.53 |
|
24 |
0.28 |
0.49 |
|
13 |
0.26 |
0.50 |
|
3 |
0.26 |
0.44 |
Table 8.16 Typical Albedo Rates
|
Surface |
Albedo |
|
Close growing crops |
0.15-0.25 |
|
Bare land surfaces |
0.05 - 0.45 |
|
Forest |
0.15 |
|
Water |
0.05 |
(The Tables of the Smithsonian Institute provide a comprehensive guide to albido rates)
Care should be taken that variables and constants are those appropriate for measurements in ° C or ° F when applying versions of the equation that may have been developed locally. Tabulated values for the components of Penman's equation are available to assist calculation and are given below. They are used with an illustrative example of Penman calculations.
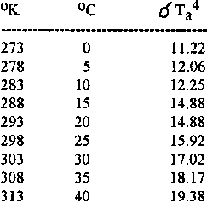
Table 8.17: Values of d
Ta4 for Different Temperatures

Table 8.18: Values of D/D + d and d/D
+ d for Different Temperatures
Table 8.19 gives values of Rs for different latitudes.
Table 8.20 gives values of possible sunshine hours for different months and latitudes.
Figure 8.13 gives saturation vapour pressure for temperature values °C and °K.

Table 8.19: Values of Rs
for Different Latitudes in mm day-1
Mid Monthly Radiation on a Horizontal Surface in mm of Water Day-1 Evaporated
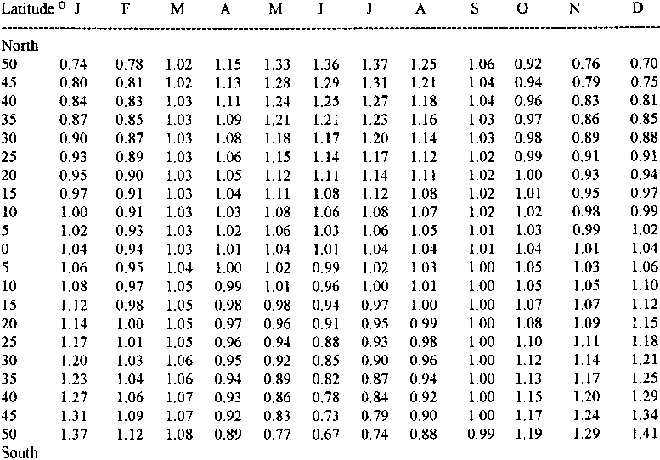
Table 8.20: Mean Possible Sunshine, N
To calculate maximum duration of sunlight for any month multiply 12 × 30 × coefficient
Local variations of Penman's equation are often developed after a comprehensive study of local climatic variables. The example below is for the semi arid and arid conditions found in southern Africa, the value of x being 0.5 for open surface evaporation and 1.0 for evapotranspiration.
Ep = D /D +d[Rs(1-r) (0.25 + 0.50 ( n/N)] - D /D +d[d Ta4 (0.32 - 0.42ed) (0.30 + 0.70 (n/N))] + d/D + d[(x + 0.0062 u) (ea - ed)] (8.39)
In this equation it is interesting to note that the term (0.32-0.42ed1/2) is always negative, thereby adding to the calculated evapotranspiration obtained from the overall formula.
Penman's equation was developed for estimates of Ep from short grass under humid conditions. These conditions are frequently not met with, though they may be simulated by the presence of wet soil after rain, shallow water bodies or irrigated conditions.
In arid and semi arid areas, localised variations in crop cover may lead to areas of crops being surrounded by hotter, drier conditions, and is sometimes referred to as the "oasis effect". In these circumstances more energy is available for evapotranspiration than indicated by measured incoming solar radiation, leading to increased and widely different localised rates of evapotranspiration.
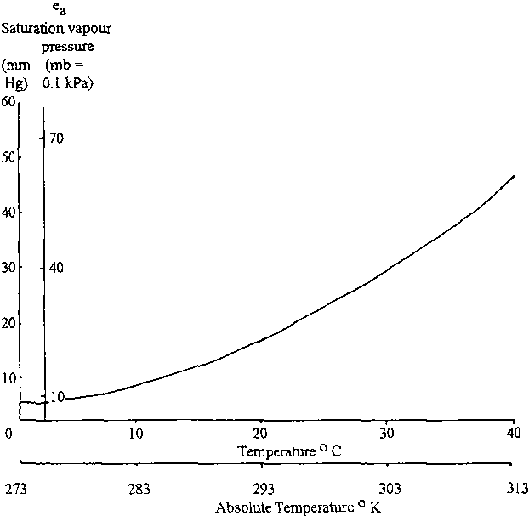
Figure 8.13: Saturation Vapour
Pressure with Temperature
A worked example of a Penman calculation is given below:
Worked Example
Substituting into equation 8.38:
Ep = 0.753 [14.6 (0.75) (0.22 + 0.55 (0.65))] - 0.753 [16.34 (0.56 - 0.09 ( 4.77)) (0.10 + 0.90 (0.65)]+ 0.247 [(0.175 + 0.0035 (125) (35.0 - 22.75)] = 0.753 [6.324] - 0.753 [1.463] + 0.247 [5.534] = 5.03 mm day-1
In addition to the difficulty of equating consumptive use to actual crop use, a difficulty shared with all empirical ED equations, one particular problem with Penman's equation is the requirement of data for a wide range of measured variables. Some work has been undertaken to relate, through regression analysis, the major components of Penman's equation with values of Ep calculated from the full equation. For example Rs which is tabulated and u the windrun which is easily measured, versus Ep could be used. Ten day mean values of evapotranspiration are often used rather than daily values and Ep does not vary greatly between locations with similar prevailing weather conditions.
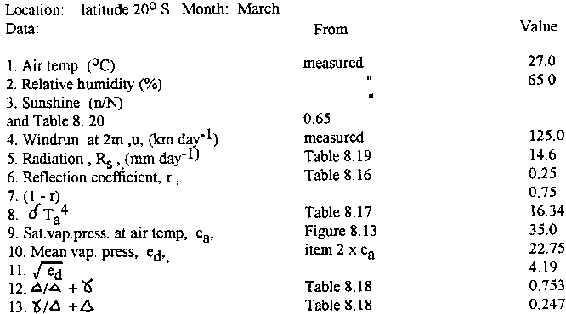
Table
In basin resources studies the problems of localised variation is not great, but in cases where localised values of actual evapotranspiration are needed, the situation is often more difficult. For example the response by plants to reduced water availability may lower actual rates of evapotranspiration from more than 60% of potential to 10% or less. The problems involved in the application of empirical formulae to estimate actual water losses by evapotranspiration go a long way to explain the continued measurement of these losses by lysimetry and other field methods.
The FAO is currently undertaking a review of methods for the calculation of evapotranspiration and is expected soon to pronounce on the methods it regards as most appropriate.
8.2.4 Sedimentation Data Analysis
The most common analysis of sedimentation data is a regression relation against runoff, often called a sediment-rating curve. The sedimentation factor may be sedimentation concentration, Co or sediment load, Qs. Such a relation may be applied to long term flow records and produces a sediment-duration curve. The best fits are given by plotting log 10 discharge against log 10 sedimentation and the best correlations are obtained by using load rather than concentration as the sediment factor. The form of the equation is:
Qs-aQb
thus log Qs = b (log Q) + log a (8.33)
The coefficient a has no particular range of values but is related to width of the channel in the form, the sediment per unit width of channel given by qs = a Qb /W.
The coefficient b however, has a lower limit, where b = 1 the concentration is constant and independent of Q, where b > 1 the concentration increases with Q. In practice, b is often from 1.4 to 2.8. The scatter of data is often wide, perhaps representing an order of magnitude at the 90% confidence limits. This may be due to random errors of sampling, laboratory procedure or the fact than the quantity of sediment in transport is related to many other physical variables than discharge alone. Figure 8.14 shows a graph of log Qs against log discharge Q.
In such a case, the regression line of the log values is often ignored, or rather replaced by a second regression line. This second regression is positioned to pass through the means of the actual values of Qs and Q, rather than the means of the log values. The line is drawn parallel to the original line, but now passes through the arithmetic values of the means, and through the mean Qs - mean Q intercept. This produces a weighted estimate of Qs for given Q and tends to reduce the large errors otherwise found.
Sample sediment concentration may be plotted in a similar way, with concentration x discharge giving the data points for Figure 8.14. It should be remembered that sediment estimates based on such relations are subject to errors in the relation and the uncertainty as to whether the relation can be applied to other periods of measurement.
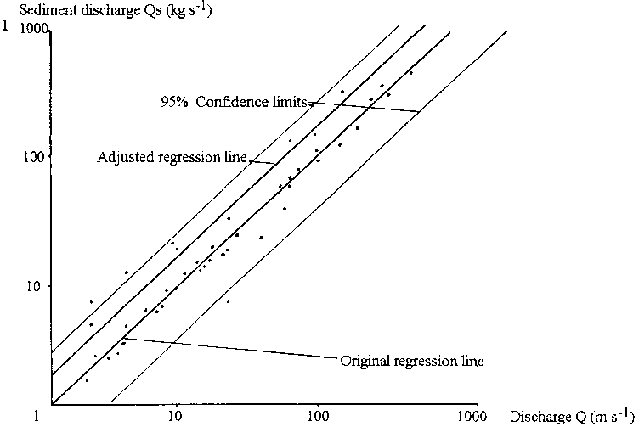
Figure 8.14: Sediment Discharge
against River Flow
Extrapolation
The extrapolation of such relations is difficult, because the value of the coefficient, b, falls with higher discharge levels and the relation is in reality non-linear on log-log plotting. Studies have shown that the sediment carrying capacity of discharge decreases with increased discharge after the concentration has reached 100 kg m-3. The physical basis of this observation is not clear. Methods of extrapolation are available according to absolute rates of sedimentation, but these may be extremely involved, using combinations of water level and grain size groups, a range of water level/discharge relations, a topographic survey of a test reach of the river, water temperature etc.
The FAO paper 37, "Arid Zone Hydrology" gives full details of the procedure (the Einstein method) which is not relevant to the scope of this handbook. It is however, the only method recommended by the FAO for the theoretical determination of sediment load and the augmentation of empirical information. In the same chapter, this paper also outlines other methods that can be used to estimate the silting of dams by sedimentary deposition.
First approximations of total sedimentation according to volume of discharge have been developed as regression for semi arid and arid regions, and while these cannot be used for design purposes, they have proven useful in generalising the order of sediment load, see Figure 8.15.
The development of regression relations is likely, as for other such relations, to be limited by geographical locality, soils, hydrological and climatic regimes etc., and the translocation of formulae from one area or even stream to another is likely to be unsuitable for any purpose other than approximate estimation.
In Figure 8.15, the form of the regression is Vs = aVb, the coefficient values are:
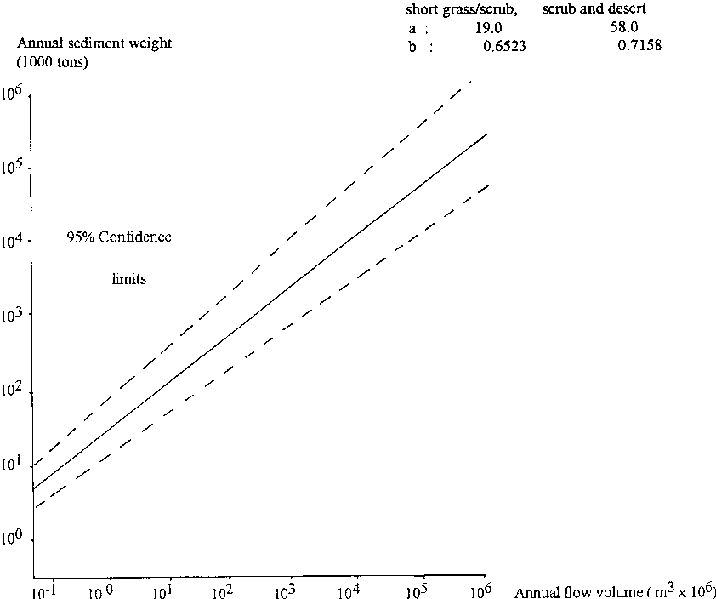
Figure 8.15: Sediment from Short
Grassland and
Scrub
Appendix E1: Critical values of the chi-square distribution
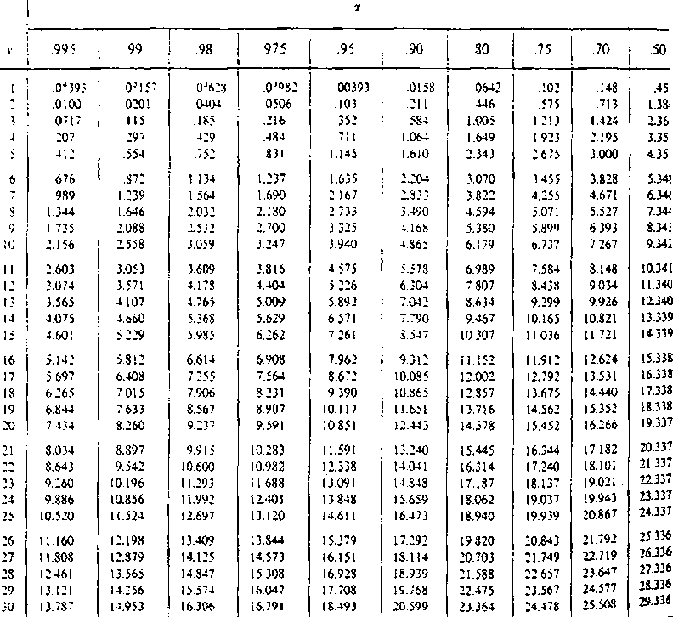
Figure
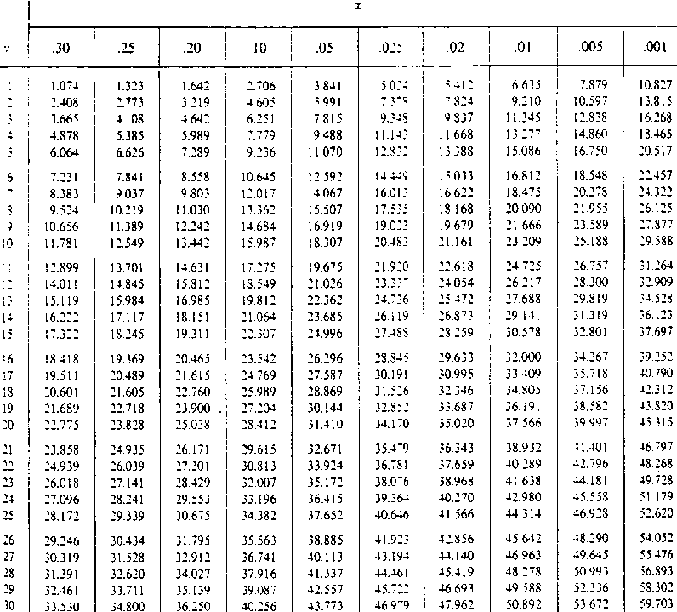
Figure
